18.03.2025

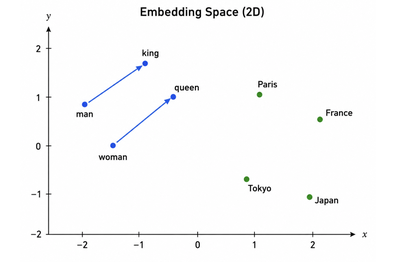
Погрузитесь в мир инноваций с DeepSeek R1! В курсе от вы узнаете, как эта крутая штука использует обучение с подкреплением, чтобы прокачать свои способности к логике. Разберёте, что такое GRPO(Group Relative Policy Optimization) и чем оно лучше старых методов PPO. Плюс, поймёте, как KL-дивергенция помогает держать модель в стабильности — всё с примерами кода и без заумных объяснений.