20.06.2026
Еще раз про то, как все устроено
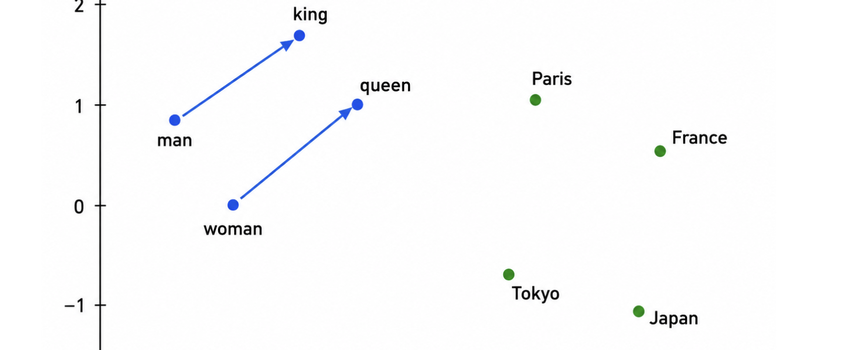
Статья - это пошаговый разбор устройства современных LLM на основе трансформеров. Все без сложной математики. Автор проведет вас от токенизации и эмбеддингов до позиционного кодирования RoPE, механизма внимания Q/K/V, multi-head attention, feed-forward-сетей где хранится большая часть знаний модели, residual stream и layer normalization, и наконец - цикла предсказания следующего токена.
Автор показывает, что большинство современных моделей реализуют общий архитектурный скелет, а различия сводятся к обученным весам, конфигурации и пост-тренировке, при этом ключевые механизмы остаются неизменными даже при появлении новых архитектур вроде Mamba или MoE.



