
Перевод статьи "RAG in Go: A Practical Implementation Using Qdrant and OpenAI". Но это будет не совсем перевод - я для примеров буду использовать GigaChat через прокси, как делал это в прошлой статье.
Одна из ключевых задач для компаний, работающих с искусственным интеллектом, - обеспечить эффективный доступ к внутренним знаниям. На первый взгляд всё просто: загрузи корпоративные документы в большую языковую модель (LLM) и дай ей генерировать ответы. Но на практике такие решения часто разочаровывают - страдают от нехватки точности, низкой скорости или высокой стоимости. В общем, желаемого качества добиться трудно.
RAG (Retrieval-Augmented Generation) - это метод, при котором языковая модель (например, GPT) сначала обращается к внешним данным, а уже потом формирует ответ. Такой подход позволяет делать интеллектуальные системы, которые выдают точные и релевантные ответы на основе ваших собственных данных.
Почему RAG - это важно
Обычные большие языковые модели ограничены тем, на чём их обучали. У них нет доступа к вашему каталогу продуктов, внутренней документации или свежим обновлениям. RAG решает эту проблему: сначала он выполняет векторный поиск в базе данных Qdrant, находит релевантные документы, а затем использует их как контекст для ответа модели.
Такой подход позволяет системе подстроиться под вашу конкретную область без дообучения LLM. Поэтому RAG отлично подходит для справочных ботов, внутренних ассистентов и поиска товаров.
Структура проекта
Этот RAG-проект на Go организован так:
go-qdrant-rag-sample/
├── .gitignore ← исключаем чувствительные файлы вроде .env
├── docker-compose.yml ← поднимаем Qdrant
├── go.mod / go.sum ← Go-модуль и зависимости
├── README.md ← обзор проекта
├── .vscode/
│ └── launch.json ← конфиг для отладки в VS Code
├── cmd/
│ └── api/
│ └── main.go ← точка входа
├── data/
│ └── products.csv ← данные товаров для эмбеддингов
├── env/
│ └── .env ← храним OpenAI-ключ (исключён из Git)
├── internal/
│ ├── api/
│ │ └── server.go ← запускает HTTP-сервер
│ ├── config/
│ │ └── env.go ← загружает переменные окружения
│ ├── models/
│ │ └── product.go ← структура данных товара
│ ├── qdrant/
│ │ ├── collection.go ← создание коллекции
│ │ ├── embedder.go ← генерация эмбеддингов
│ │ ├── ingester.go ← индексация данных в Qdrant
│ │ ├── rag.go ← основная RAG-логика: поиск + LLM
│ │ └── search.go ← семантический поиск
│ └── utils/
│ └── csvreader.go ← читает товары из CSV
Полный код можно взять на GitHub: yuniko-software/go-qdrant-rag-sample
Как запустить проект
Сначала запускаем Qdrant:
docker-compose up -d qdrant
Создаём новый .env файл в директории env/ и указываем правильный ключ для OpenAI API:
OPENAI_API_KEY=sk-your_key
Запускаем наш сервер:
go run ./cmd/api
И теперь можно выполнять запросы к серверу:
http://localhost:8080/rag
Пример запроса
Теперь можно погонять тестовые запросы:
GET http://localhost:8080/rag?q=sonyPS5&top=10
Пример ответа:
{
"question": "sonyPS5",
"total": 2,
"answer": [
{
"description": "The Sony PlayStation 5 Console delivers ...",
"name": "Sony PlayStation 5 Console",
"price": 499.99
},
{
"description": "PlayStation 5 Digital Edition ...",
"name": "Sony PlayStation 5 Digital Edition",
"price": 399.99
}
]
}
Как работает RAG-система
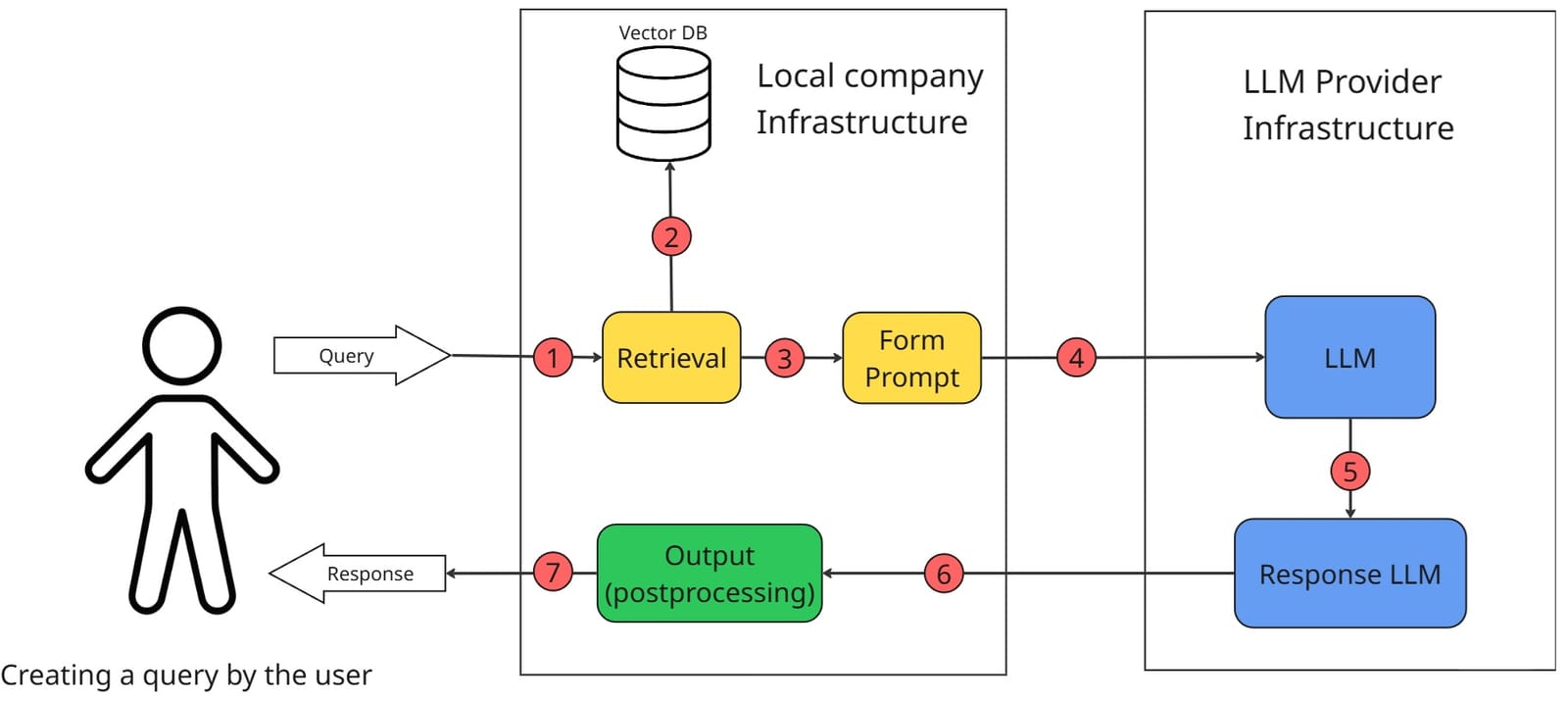
Пользователь задаёт вопрос, который поступает в систему. Запрос превращается в вектор с помощью модели эмбеддингов.
Механизм поиска (retrieval) выполняет семантический анализ и ищет по базе данных (например, Qdrant), чтобы найти самые релевантные фрагменты текста:
func SearchProducts(query string, topK int, maxPrice *float64) ([]SearchResult, error) {
embedding, err := GetEmbedding(query)
if err != nil {
return nil, err
}
request := map[string]interface{}{
"vector": embedding,
"top": topK,
"with_payload": true,
"with_vector": false,
}
if maxPrice != nil {
request["filter"] = map[string]interface{}{
"must": []map[string]interface{}{
{
"key": "price",
"range": map[string]interface{}{
"lt": *maxPrice,
},
},
},
}
}
host := config.QdrantHost()
client := resty.New()
resp, err := client.R().
SetHeader("Content-Type", "application/json").
SetBody(request).
Post(host + "/collections/products/points/search")
if err != nil {
return nil, err
}
var result struct {
Result []SearchResult `json:"result"`
}
if err := json.Unmarshal(resp.Body(), &result); err != nil {
return nil, err
}
return result.Result, nil
}
Найденные фрагменты склеиваются в единый контекст. При формировании промпта также задаются правила интерпретации контекста - должна ли модель строго опираться только на контекст или может добавлять что-то от себя.
Готовый промпт отправляется в LLM, которая на его основе генерирует ответ.
func RunRAG(question string, topK int) (RAGResponse, error) {
results, err := SearchProducts(question, topK, nil)
if err != nil {
return RAGResponse{}, fmt.Errorf("retrieval error: %w", err)
}
// Build context from Qdrant results
context := ""
for _, r := range results {
name := r.Payload["name"]
desc := r.Payload["description"]
context += fmt.Sprintf("- %v: %v\n", name, desc)
}
prompt := fmt.Sprintf(`
You are a helpful assistant. Given the product context below, respond with a valid JSON array of the best-matching product payloads.
Each payload must include:
- "name": string
- "description": string
- "minimum_order": integer
- "price": number
- "price_currency": string
- "supply_ability": integer
DO NOT include any "id" or "score" fields.
DO NOT wrap the response in triple backticks or Markdown formatting.
Context:
%s
Question: %s
Respond ONLY with the array of payloads.`, context, question)
apiKey := os.Getenv("OPENAI_API_KEY")
if apiKey == "" {
return RAGResponse{}, fmt.Errorf("missing OPENAI_API_KEY")
}
reqBody := map[string]interface{}{
"model": "gpt-4o-2024-08-06",
"messages": []map[string]string{
{"role": "user", "content": prompt},
},
}
encoded, _ := json.Marshal(reqBody)
req, _ := http.NewRequest("POST", "https://api.openai.com/v1/chat/completions", bytes.NewBuffer(encoded))
req.Header.Set("Content-Type", "application/json")
req.Header.Set("Authorization", "Bearer "+apiKey)
res, err := http.DefaultClient.Do(req)
//...
}
Ответ от LLM иногда содержит лишние детали или технические метаданные. Поэтому он проходит постобработку: ненужное удаляется, результат приводится к читаемому виду. После этого система возвращает пользователю готовый, понятный ответ.
Подключаем GigaChat
Сразу ссылка на отредактированный проект на GitHub akovardin/go-qdrant-rag-sample
В целом всё готово к использованию. Но было бы неинтересно оставлять как есть и не попробовать подключить наши родные сберовские модельки и API. Обратите внимание: эмбеддинги оплачиваются отдельно.
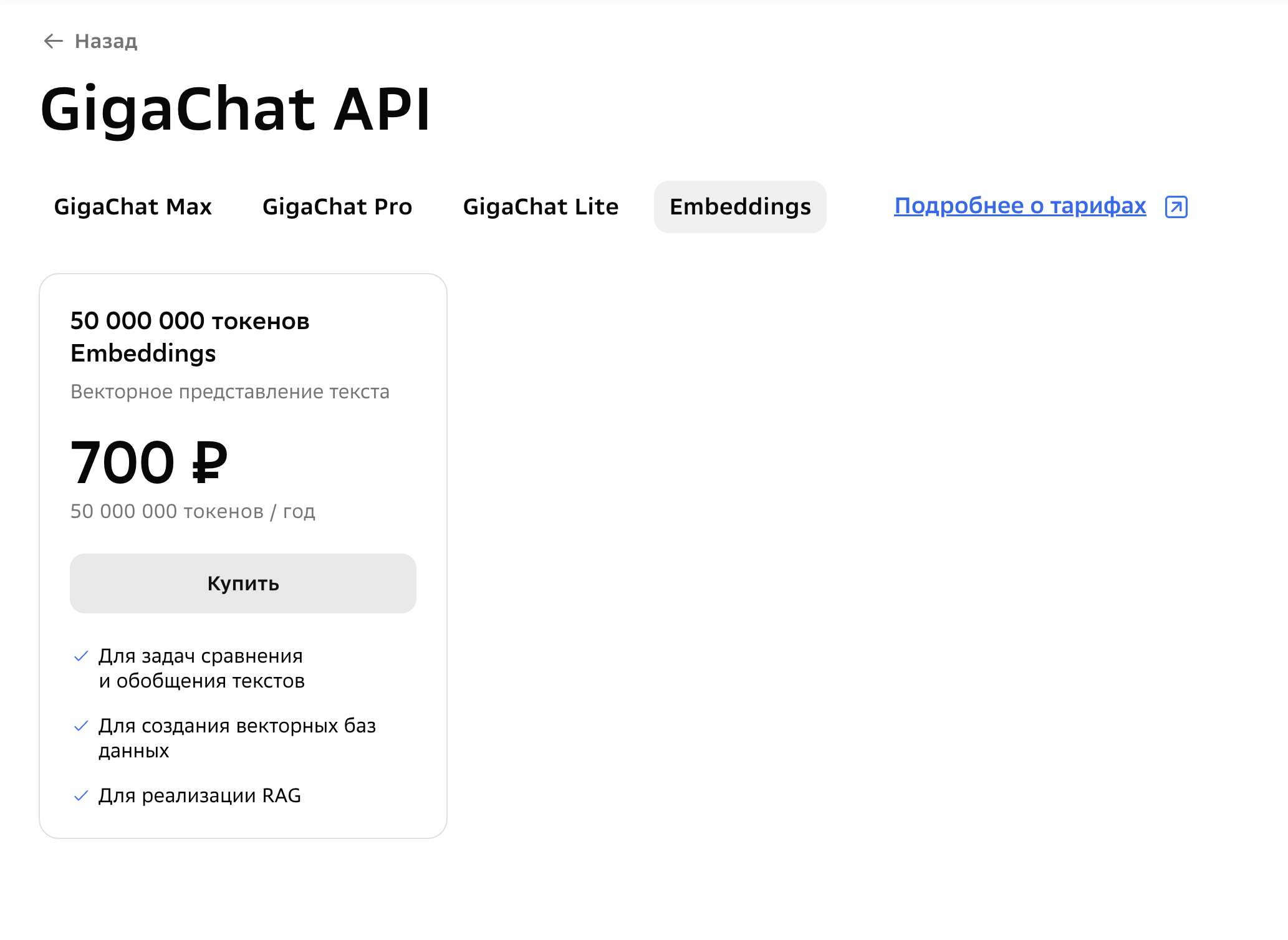
Для этого нам понадобится проект, про который я уже писал в прошлой статье - прокси для GigaChat openai-provider-gigachat.
Чтобы всё заработало, нужно переделать пример RAG и заменить URL https://api.openai.com/v1 на http://localhost:8080/v1. Токен можно указать любой, потому что доступы к GigaChat задаются на уровне прокси.
const base = "http://localhost:8080/v1"
func RunRAG(question string, topK int) (RAGResponse, error) {
// ...
req, _ := http.NewRequest("POST", base + "/chat/completions", bytes.NewBuffer(encoded))
req.Header.Set("Content-Type", "application/json")
req.Header.Set("Authorization", "Bearer "+apiKey)
res, err := http.DefaultClient.Do(req)
//...
}
Кроме URL, нужно изменить модель для эмбеддингов. GigaChat API предлагает три варианта:
Embeddings- базовая модель для векторного представления текстовEmbeddings-2- улучшенная версия базовой моделиEmbeddingsGigaR- продвинутая модель с большим контекстом
Для тестов возьму самую простую - Embeddings. Документация по векторному представлению текста через GigaChat API.
func GetEmbedding(text string) ([]float32, error) {
apiKey := os.Getenv("OPENAI_API_KEY")
if apiKey == "" {
return nil, fmt.Errorf("missing OPENAI_API_KEY")
}
client := resty.New()
requestBody := map[string]interface{}{
"input": text,
"model": "Embeddings", // вот тут меняем модельку
}
//....
}
И ещё одно небольшое изменение в коде примера - нужно правильно указать основную модель:
func RunRAG(question string, topK int) (RAGResponse, error) {
results, err := SearchProducts(question, topK, nil)
if err != nil {
return RAGResponse{}, fmt.Errorf("retrieval error: %w", err)
}
// Build context from Qdrant results
context := ""
for _, r := range results {
name := r.Payload["name"]
desc := r.Payload["description"]
context += fmt.Sprintf("- %v: %v\n", name, desc)
}
prompt := fmt.Sprintf(`
You are a helpful assistant. Given the product context below, respond with a valid JSON array of the best-matching product payloads.
Each payload must include:
- "name": string
- "description": string
- "minimum_order": integer
- "price": number
- "price_currency": string
- "supply_ability": integer
DO NOT include any "id" or "score" fields.
DO NOT wrap the response in triple backticks or Markdown formatting.
Context:
%s
Question: %s
Respond ONLY with the array of payloads.`, context, question)
apiKey := os.Getenv("OPENAI_API_KEY")
if apiKey == "" {
return RAGResponse{}, fmt.Errorf("missing OPENAI_API_KEY")
}
reqBody := map[string]interface{}{
"model": "GigaChat-2-Max", // вот тут меняем модельку
"messages": []map[string]string{
{"role": "user", "content": prompt},
},
}
encoded, _ := json.Marshal(reqBody)
//...
}
Теперь укажем настройки для RAG в файле env/.env:
OPENAI_API_KEY=any-token
QDRANT_HOST=http://localhost:6333
Запускаем Qdrant:
docker-compose up -d qdrant
И запускаем само приложение:
go run ./cmd/api
Эта команда инициализирует коллекцию Qdrant (если её нет), проверяет, пуста ли коллекция, при необходимости загружает набор данных из data/products.csv и запускает REST API сервер на http://localhost:8080.
Но тут мы можем получить ошибку в логах самого Qdrant:
2026-04-02T22:12:43.818910Z INFO actix_web::middleware::logger: 172.21.0.1 "PUT /collections/products/points HTTP/1.1" 200 96 "-" "go-resty/2.16.5 (https://github.com/go-resty/resty)" 0.003375
2026-04-02T22:12:43.819727Z WARN collection::collection_manager::collection_updater: Update operation declined: Wrong input: Vector dimension error: expected dim: 1536, got 1024
Чтобы исправить ошибку, нужно немного подправить создание коллекции в нашем примере:
func CreateCollection() error {
client := resty.New()
body := map[string]interface{}{
"vectors": map[string]interface{}{
"size": 1024, // указываем размерность
"distance": "Cosine",
},
}
//...
}
Векторизация и загрузка продуктов занимают ощутимое время. После завершения загрузки вы должны увидеть такое сообщение:
Теперь попробуем тот же самый запрос, но уже с GigaChat под капотом:
GET http://localhost:8080/rag?q=sonyPS5&top=10
И получаем отличный результат:
{
"question": "sonyPS5",
"total": 4,
"answer": [
{
"id": "f8351be9-e70e-4f6a-bb29-11d3aeb15d0b",
"payload": {
"description": "The Sony PlayStation 5 Console offers lightning-fast load times, stunning 4K graphics, and immersive gaming with the DualSense wireless controller.",
"minimum_order": 1,
"name": "Sony PlayStation 5 Console",
"price": 499.99,
"price_currency": "USD",
"supply_ability": 5000
}
},
{
"id": "c8e5f1eb-b33c-47f1-812e-d8e1e8fbc8f1",
"payload": {
"description": "The Sony PlayStation 5 Console offers next-gen gaming performance with ray tracing, ultra-fast loading, and a new controller for an immersive gaming experience.",
"minimum_order": 1,
"name": "Sony PlayStation 5 Console",
"price": 499.99,
"price_currency": "USD",
"supply_ability": 2000
}
},
{
"id": "c7a6894e-ea0d-46c8-b421-21879c024db4",
"payload": {
"description": "The Sony PlayStation 5 Console offers ultra-fast load times, stunning visuals with ray tracing, and immersive gameplay for a next-gen gaming experience.",
"minimum_order": 1,
"name": "Sony PlayStation 5 Console",
"price": 499.99,
"price_currency": "USD",
"supply_ability": 2000
}
},
{
"id": "c3a7b8c5-bd89-4027-b723-5576c4b4f1b3",
"payload": {
"description": "The Sony PlayStation 5 Digital Edition offers next-gen gaming performance with an ultra-fast SSD, stunning visuals, and a wide variety of exclusive games.",
"minimum_order": 2,
"name": "Sony PlayStation 5 Digital Edition",
"price": 499.99,
"price_currency": "USD",
"supply_ability": 6000
}
}
]
}
На тестовых данных работает не хуже OpenAI.
Заключение
Этот проект показывает, как разработчики могут построить полноценный RAG-конвейер на Golang - от приёма данных и их векторизации до векторного поиска и генерации ответа. Используя Go, вы получаете не только производительность и простоту, но и чёткое, модульное представление о том, как устроена RAG-система и что происходит "под капотом".
Поэкспериментировав с GigaChat, могу сказать: как минимум для базовых задач эти модели работают не хуже других.